
Chi sono

Sono Roberto Cananzi, più spesso conosciuto come il BaK.
Dopo un percorso di studi classici ho iniziato a lavorare, fin da giovanissimo, nel settore dell'informatica.
Allo studio di diversi linguaggi di programmazione segue la scrittura di un framework (Universalis) che, permettendo l'introduzione della grafica su datati computer attrezzati del vecchio DOS, sarà la base di molti programmi aziendali auto-prodotti in quel periodo.
Dopo il diploma dedico alcuni anni al volontariato tramite l'assistenza di anziani e di ragazzini in difficoltà sociale, oltre a partecipare alla distribuzione del cibo nei quartieri difficili della città.
Con la fine degli anni '90 inizio ad interessarmi all'open source come alternativa etica e libera per l'utilizzo e la diffusione della tecnologia.

Nel 2002 creo il canale IRC #ReggioCalabria sul network Azzurra, una chat in tempo reale di cui scrivo sito e forum di riferimento. La community del canale negli anni cresce e diventa punto di incontro per reggini ed emigrati. In diversi quartieri della città le attività commerciali espongono il volantino della chat. Intanto 'la Betty' (figura femminile che rappresenta la città nel logo della chat) arriva anche sul sito del network che certifica #ReggioCalabria come canale ufficiale della città e uno tra i più visitati del network. Nel 2004 'regalerò' alla community stessa il progetto, che sento per me concluso, comprensivo del forum diventato un innovativo spazio online per la promozione di eventi in città e l'organizzazione dei 'meeting': eventi di incontro che ripropongono dal vivo la cordialità della chat.
Nel 2003 fondo la Red Rose per continuare in proprio vendita e assistenza, oltre ad iniziare progetti di ricerca e promozione del software open source.
L'esperienza maturata nella programmazione mi ha portato a lavorare principalmente con le aziende ed in ambiti imprenditoriali, in particolare riguardo la migrazione da software commerciale verso software libero.
Nel 2005 scrivo A.R.S. (All-purpose Roleplaying System), un sistema universale per giochi di ruolo. Libero ed essenziale (un solo flyer di una pagina contro gli ingombranti manuali a cui il settore è abituato a confrontarsi), l'A.R.S. trova ideale diffusione nell'ambiente di internet e crea in città un gruppo di giocatori e appassionati che si ritrova regolarmente in diverse serate di gioco.

Nel 2007, alla fine di uno stage di improvvisazione teatrale, scrivo A.R.S. Live: la versione per gioco di ruolo dal vivo dell'A.R.S.
Gli appuntamenti di gioco si infittiscono, affiancando al gioco da tavolo anche eventi del tutto originali ed inediti basati sul manuale Live: ogni mese tante persone si ritrovano per 'vivere' per una sera il loro personaggio all'interno di un vero e proprio evento dal vivo.
Da questo momento in poi il gioco di ruolo in Calabria sarà indentificato (tra giocatori e riviste del settore) nell'A.R.S. che continua la sua diffusione.
Nel 2007 prendo parte al tavolo anti-pirateria sul web, schierandomi a favore della libertà di espressione e di diffusione dell'arte e promuovendo l'importanza dell'arte auto-prodotta e finanziata dal basso.
Nel 2008 ottengo un terreno con un rudere in disuso, all'interno di un quartiere della periferia reggina. Partendo dall'allaccio di acqua ed energia elettrica, fino ad elaborare soluzioni del tutto innovative basate sui materiali riciclati ed eco-compatibili, prende forma la struttura 'House of ARS' che diventa anche sede del primo collettivo artistico reggino: il collettivo ARS.
Il collettivo sfrutta gli eventi di improvvisazione teatrale ARS per raccogliere appassionati di arte e spettacolo, offrendo uno spazio libero dove potersi incontrare e produrre le loro idee.
Nel 2009 l'House diventa anche il primo spazio di coworking reggino: un laboratorio creativo in cui, tra l'altro, prendono forma tutti gli allestimenti ed i costumi di scena. Nello stesso anno è la prima struttura ad ospitare un evento cosplay in Calabria, offrendo il laboratorio per cosplay autoprodotti. Nel 2010 i cosplay qui prodotti andranno a vincere il primo concorso regionale del settore.
Dal 2008 al 2010 il collettivo ARS partecipa alla produzione di svariati video ed iniziative sul territorio.

Nel 2009 l'House è la prima struttura reggina ad offrire una connessione internet libera ed è la prima ad ospitare una rete informatica interamente basata su sistemi open source.
Il 15 marzo 2010 partecipo al 'No mafia day' con il collettivo ARS e proprio al laboratorio dell'House viene chiesto di confezionare le lettere che andranno ad aprire il corteo.
Il 25 marzo 2010, in quello che sarà ricordato come un momento buio dell'informazione e della libertà di espressione in Italia, l'House è l'unica struttura calabrese ad affrontare il pericolo di libertà di informazione e proporre il web come alternativa ai media tradizionali, ospitando anche l'evento nazionale 'Rai per una notte'.
Nel settembre del 2010 il collettivo ARS viene congelato e continuerò a proporre le iniziative solo come il BaK.

Il 10 ottobre 2010 organizzo la 'Zombie Walk @ Reggio Calabria': una sfilata in centro a cui segue una intera serata di concerti ed esposizioni artistiche. Evento dedicato alla voglia di rinascita cittadina, tramite la metafora degli zombie, e che raccoglierà di li in poi ogni anno centinaia di persone.
Ironicamente, durante un normale controllo della SIAE, un funzionario definisce la struttura 'House of BaK' e con questo nome verrà riconosciuta negli anni a seguire.
Dal 2010 l'House si affermerà come luogo di arte unico nel suo genere, al di fuori di ogni contesto politico e commerciale offrendo spazio ad eventi di assoluto rilievo nel contesto artistico del sud, ospitando artisti che spaziano dal popolare al punk, con un calendario mensile di eventi che comprende tutte le arti, dal cinema al teatro passando per concerti e reading letterari.
Nel 2011 sono chiamato dall'Unione degli Studenti e Legambiente nell'organizzazione della tappa reggina del progetto nazionale 'I giovani cambiano il clima che cambia', portando centinaia di ragazzi a ballare una conga in pieno centro cittadino. L'evento vuole sensibilizzare sul problema del riscaldamento globale ed è seguito da una mostra fotografica allestita su un treno speciale che percorre tutta l'Italia nelle settimane successive.
Nel 2011 scrivo la prima versione di 'Hot Coffee CMS' uno script PHP che, 'agganciandosi' a qualsiasi tema grafico per siti web, permette di attivare in pochi minuti interi siti. I siti così creati, oltre a rispettare tutti gli standard del World Wide Web Consortium, permettono di evitare qualsiasi servizio centralizzato o 'fai da te' tra quelli disponibili sul web e, grazie alla sua grande elasticità, permette di sviluppare anche siti molto complessi utilizzando semplici soluzioni open source. Lo script è grande meno di 4 kb ed è compatibile con qualsiasi dispositivo fisso e mobile.

Viene messo online nel 2011 il sito ilbak.it che raccoglie, oltre ad un blog con tutte le notizie sulle mie attività, una newsletter tramite la quale ogni settimana gli iscritti ricevono una mail che riporta eventi e informazioni su quanto organizzo. In poche settimane le iscrizioni superano il migliaio di indirizzi mail attivi.
Pochi mesi dopo viene attivano un piccolo negozio online che vende gadget rigorosamente prodotti a chilometro zero, portando le giovani eccellenze locali a lavorare per la prima volta su un brand pensato per il web. Sarà tra le prime realtà italiane ad accettare una criptovaluta grazie alle transazioni tramite protocollo Bitcoin.
Nel 2013 alcuni miei racconti brevi sono pubblicati all'interno del progetto letterario CENTOPAROLE raccogliendo messaggi di consenso tra gli altri scrittori ed i lettori del volume.

Nel novembre del 2013 viene pubblicato sul web 'I racconti della città di Gry'. Il racconto si svolge nella immaginaria città di Gry, da anni flagellata da una sanguinosa guerra con una città vicina. Ma tra le macerie della città tante vite sono costrette a convivere e sopravvivere alla guerra, tra queste la vita della giovane Ayrilis, una curiosa ed intraprendente ragazza che sogna di riuscire a fuggire da Gry e conoscere il mondo letto solo di nascosto su qualche libro. L'intero ricavato della vendita de 'I racconti della città di Gry' è devoluto alla ONLUS 'Scuola di Pace' per finanziare una spedizione umanitaria ai confini col territorio siriano, afflitto dalla guerra.

Il 25 novembre 2013, in occasione della giornata mondiale contro la violenza sulle donne ho modo di tenere un reading di mie poesie a piazza Italia, nel centro di Reggio Calabria. E' solo una delle tappe del reading letterario con cui porto in locali e spazi pubblici le poesie che ho scritto negli anni, pubblicate tramite il sito e riprese da diversi siti e riviste del settore.
Nell'aprile del 2013 viene pubblicato l'ebook 9 storie di ordinaria innovazione che raccoglie anche una mia intervista riguardo l'esperienza sul territorio e l'innovazione.
Dal giugno 2013 l'abitudine di organizzare una cena aperta e condivisa all'House ogni settimana diventa un programma radiofonico: La Cena dei Reggini riprende la cena che si tiene all'House ogni settimana già da tempo e porta tramite radio, video e podcast, la vita dell'House verso le case di molti curiosi in giro per il mondo.
Il format è scritto da me e si presenta come un contenitore all'interno del quale commensali che prendono realmente parte ad una cena possono commentare notizie, presentare le loro idee o artisti possono partecipare come ospiti per condividere la loro arte.
La Cena diventa una meta ambita per tutta l'arte indipendente che vuole presentarsi sul web ma non solo... Negli anni ospiterà anche temi più importanti come quello delle armi chimiche siriane smaltite nel Mediterraneo o la voce di imprenditori in difficoltà.
A margine dell'indiscusso ruolo di intrattenimento, La Cena dei Reggini ogni settimana raccoglie del cibo che viene condiviso per diventare una vera cena per le famiglie reggine nei guai. Primo esempio di food sharing in città, permette per la prima volta l'accesso al cibo al di fuori di bandiere politiche o religiose.

Nell'agosto del 2014 fondo 'La Gilda degli Artisti', un'associazione che vuole seguire gli eventi da me organizzati e portare la filosofia che ha mosso l'House fin qui anche oltre la mia singola persona. In pochi giorni La Gilda guadagna associati e diventa punto d'incontro per artisti reggini e non.

Utilizzando l'House come sede, La Gilda riesce a creare un ambiente propositivo e produttivo di arte, in cui offrire spazio e consulenza agli artisti indipendenti liberamente e al di fuori da ogni contesto politico.
A seguire presenterò swibook in diversi eventi tra cui la prima presentazione tenutasi allo Spazio Open di Reggio calabria, che attira subito l'attenzione dei videogiocatori reggini.
Nel febbraio 2019 sono ospite dell'emittente radiofonica Antenna Febea per una lunga intervista in cui ho modo di parlare dei miei progetti nel mondo dei videogiochi e delle mie esperienze nel campo dell'ospitalità.
E' qui che per la prima volta parlo di un'idea lungimirante: utilizzare location reali come scenario per ambientare i prossimi swibook.
Inizia un lungo processo di scrittura e perfezionamento della piattaforma online che mi porta anche a visitare diverse location del sud Italia proposte come futuri cornici dei miei racconti interattivi.
A dimostrazione della grande attesa su questo nuovo progetto con la pubblicazione del primo swibook, Ritorno nel Castello, il numero di visitatori diventa così elevato da mandare in crash il sito, suggerendomi di potenziare ulteriormente il lato tecnico della piattaforma.
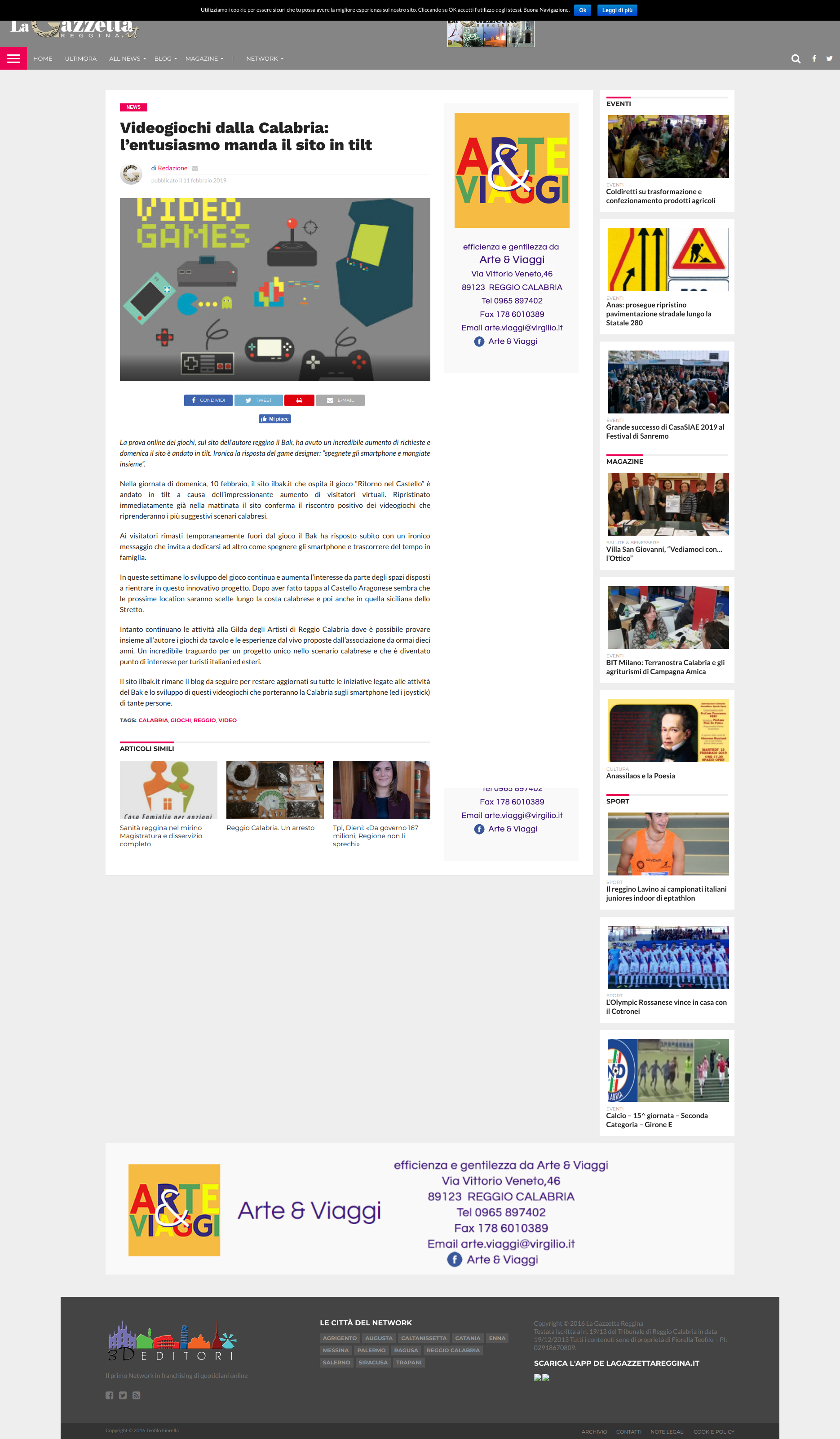
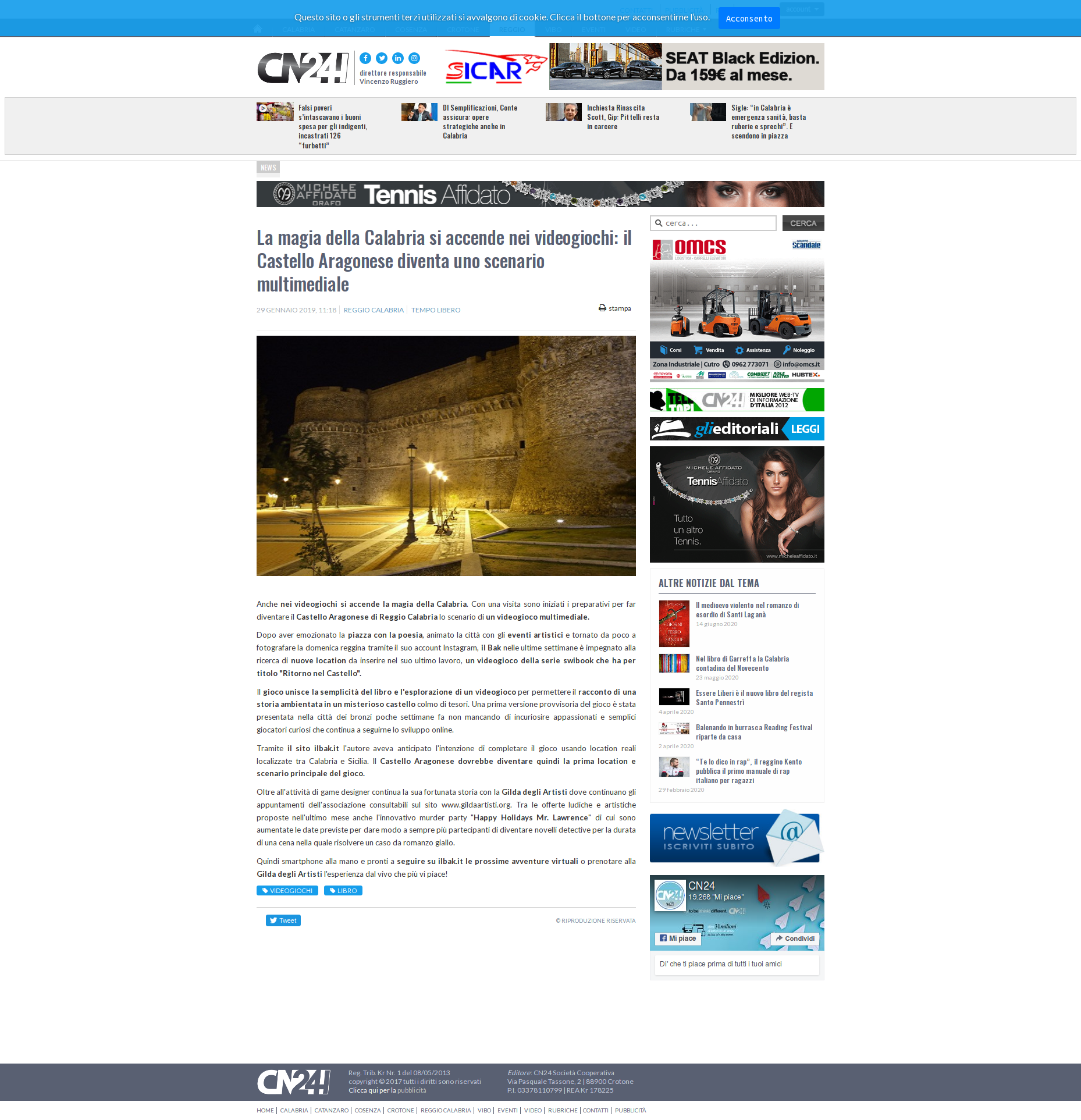
Dopo un'articolata trattativa mi viene concessa una giornata di riprese all'interno del Castello Aragonese di Reggio Calabria che sarà destinato a diventare ambientazione di uno dei prossimi swibook.
E' la prima volta che questa location storica entra nel mondo dei videogames e le immagini delle riprese fanno ancora una volta notizia in città.
A maggio 2019 creo Flute, un addon per la gestione degli utenti nei siti web. L'esperienza maturata con la piattaforma ludica mi suggerisce di centralizzare le informazioni degli iscritti ai siti e poter offrire dei servizi dedicati ma più modulari.
Nell'aprire 2020 creo Ticket, un altro addon per siti che gestisce i messaggi di informazioni e richieste di prenotazione da parte dei visitatori dei siti.

Nel maggio 2020 pubblico Denti, uno swibook molto breve che riprende il tema della solitudine e dell'amicizia, oltre a riflettere il sentimento vissuto da un mondo chiuso in casa dal lockdown.
Ancora nel maggio del 2020 creo Bitcoda. Un nuovo servizio online che gestisce tramite dei codici crittografici le code e gli ingressi contingentati in luoghi pubblici e attività commerciali. Il servizio è fornito gratuitamente e attira l'attenzione di molti operatori del settore e gestori di locali pubblici in Italia.
A luglio del 2020 sono tra i Mentor italiani di Italy of Tomorrow, iniziativa della Fondazione GaragErasmus con l’obiettivo di trovare soluzioni immediate, innovative e utili alla crisi economica e sociale causata dalla pandemia di Covid-19.
Nel 2021 conseguo il certificato in New digital technologies prima con un corso dell'Università Federico II di Napoli, poi ripetendo l'esame sulla piattaforma americana EdX per ottenere il riconoscimento internazionale.

Agli inizi del 2023 partecipo al Tech-Camp di Epicode (riguardo Cyber-Security, Full Stack Development e Data Analysis).
Nel 2023 realizzo la guida multimediale del Museo di Medma (Rosarno, RC). Tramite un sistema di riconoscimento biometrico e sintesi vocale il visitatore è riconosciuto e guidato lungo il percorso del museo. Eccetto una prima selezione della lingua non sono richieste altre azioni, permettendo al visitatore di ascoltare il testo delle didascalie e toccare con mano delle riproduzioni in 3D di alcuni reperti.

Nei primi mesi del 2023 realizzo Questa è una fanzine, oggetto d'arte sotto forma di rivista che contiene il progetto di un format crossmediale nuovo che prenderà il nome di pxzine. Una piattaforma digitale raccoglie ed espone diversi contenuti organizzati in sezioni (flow) distinte tra loro, a queste si può affiancare una fanzine cartacea: rivista stampata a basso costo e destinata a spazi pubblici e locali.
Dono uno dei prototipi al direttore dell'Accademia di Belle Arti di Reggio Calabria e successivamente, tramite l'assemblea studentesca, presento creazine l'edizione di pxzine che diventerà strumento di condivisione e memoria storica dei giovani artisti dell'Accademia.
Nel maggio 2023 realizzo il concept ed il web development del Tecno-bazar, installazione realizzata all'interno dell'Accademia di Belle Arti di Reggio Calabria per il workshop Ambientare l'Esperienza in collaborazione con Spazio Taverna (Roma).

Nel luglio 2023 conseguo il certificato in Europrogettazione e Gestione di Impresa culturale.
Tra agosto e settembre prendo parte ad un workshop sulla Street Art. L'esperienza sul campo del workshop mi permetterà di incontrare tre noti Street artisti italiani: Massimo Sirelli, Giovanni dallo Spazio ed Emauele Poki.
Il 16 settembre realizzo le Barchette a Colori, opera in poster art sulla sede della Lega Navale che si affaccia sul lungomare di Pellaro (RC).

Le mie successive visite alle Barchette a Colori diventano piccole feste in strada improvvisate dove pellaresi e passanti curiosi si divertono a seguire i lavori di manutenzione dei poster e chiacchierare.
Il 29 settembre conseguo l'attestato in Street Art con New Training Theatre.
Il 3 ottobre il mio intervento Narrazioni 2.0 nel futuro del racconto: il nuovo story telling nell'era digitale apre il XIV Mediterranean Experiences Festival (RC)

La notte del 12 novembre sono tra gli italiani invitati dall'Internet Archive all'evento online AI @ IA: Research in the Age of Artificial Intelligence trasmesso da San Francisco.
 Certificate completition Roberto il Bak Cananzi - www.ilbak.it")
Il 21 novembre completo il corso Generative AI for Executives di Amazon Web Services
